

Computer Aids for VLSI Design
Steven M. Rubin
Copyright © 1994
|
Section 2 of 7 | |
A very important feature of database representation is flexibility. In VLSI design, there seems to be no limit to the analysis and synthesis tools that can be used. All these tools manipulate different information, which must be represented. Therefore the representation must be flexible enough to contain new information wherever and whenever needed. To achieve this flexibility, the representation must not have any inherent limits. For example, fixed-sized arrays are generally a bad idea because they cannot adapt to unusual design needs. Experience has shown that no preconceived limits to the design activity are going to be acceptable to every designer. Just when it appears that one million gates is enough for a layout, there will be a demand for ten million. Just when it seems that only 50 layers are needed for integrated circuit fabrication, some process engineer will propose 60. Even simple user-interface attributes, such as the number of characters in a cell name, cannot be determined in advance.
The best way to achieve flexibility is to throw out the fixed-array construct and use linked lists [Knuth]. Linked lists are a better way to describe varying-length information because they consume less space for small tasks and extend cleanly for the big jobs. The list contains objects, which are records of data that are scattered randomly in memory. Ordering of the objects is done by having a list head pointing to the first object and a link in each object that points to the next object. A special "null" pointer in the last object identifies the end of the list.
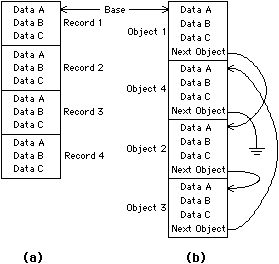
Figure 3.1 shows the difference between linked lists and arrays. In this figure, four records of data are represented with three data items per record. The array representation in Fig. 3.1(a) stores the records in sequential array order. Objects are referenced by index so the addressing of the Data B value of record N requires access to location Base + N × 3 - 2 of memory. The linked-list technique shown in Fig. 3.1(b) references objects by direct memory pointers so addressing of the Data B value of the record at address N only requires access to location N + 1. To allow for an unlimited number of data, objects can be allocated from the freespace outside the extent of the design program rather than taken from preallocated memory inside the system.
The advantages of linked lists are their shorter computation when addressing, their unlimited expandability, and the ability to insert or delete records in the list without having to move memory. The disadvantages of linked lists are the extra storage space that the links consume and the fact that finding an entry by its position in the list requires search. Extra storage should not be a concern, since time is usually more important than space. The problem of searching for an entry by its index in a list is rarely encountered in a pointer-based system because there are few if any index values.
One decision that must be made when using linked lists of objects is whether to make the lists doubly or singly linked. A singly linked list is one that has pointers in only one direction (to the "next" object). A doubly linked list points in both directions (to the "next" and the "previous" objects). Doubly linked lists are faster when insertions or deletions are being made, because more information is available for pointer manipulation. However, they take up more space and do not always produce a noticeable speed improvement. The design system programmer must determine the needs of each situation and decide whether or not to use doubly linked lists.
Every object in the database is a record that contains data items. These items are attributes that have names, values, and often specific types associated with them. Figure 3.2 shows typical attributes for a transistor object. In practice, there is a never-ending set of attributes that must be represented, caused by the never-ending set of synthesis and analysis tools. Each tool is used to manipulate a different aspect of the object, so each introduces new attributes. Given that a representation should place no limits on the design activity, it is necessary that the creation of object attributes be similarly flexible. Since it is impossible to determine in advance exactly which data entries are going to be needed when planning a record organization, the program must be able to create new attribute entries during design without any prearrangements with the database.
| ||||||||||||||||||
| FIGURE 3.2 Attribute/value pairs for a transistor. | ||||||||||||||||||
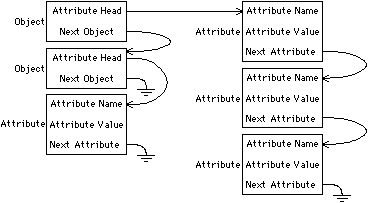
The most general scheme for expandable storage of object attributes is to use a linked list of attributes and their values. In such a scheme, an object consists of nothing but a list head that links its attribute/value records (see Fig. 3.3). This scheme is used in Lisp-based design systems [Batali and Hartheimer; Brown, Tong, and Foyster]. It has the disadvantage of making the system very slow because search is required to find an object's attribute values. To speed up attribute access, a hashing table can be stored in the object. Such a table is an array that gives initial guesses about where to look in the attribute list. Although this technique speeds access, that speed will degrade when the number of attributes grows larger than the size of the hash table. Also, hashing requires some algorithm to produce the hash key and that, too, will add delay.
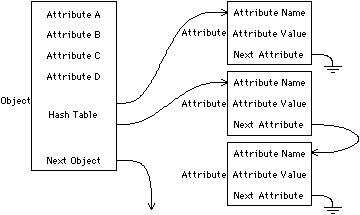
A good compromise between speed and flexibility is to use a combination of fixed record entries and additional hashed attributes (see Fig. 3.4). Records with preassigned attribute slots are the very fastest, so they should be used for the most frequently accessed entries. One of those preassigned slots can then be the hash table that references the less frequently accessed attributes. Inside the design system, the code to access attributes can usually be tailored to use the proper method. Those pieces of code that cannot know the storage method of attributes in advance will have to search the hash table first and then step through the names associated with the fixed attributes. To speed such programs, hashed entries can be created for fixed attributes so that the hash table is the only place that need be consulted. In order to save memory, these additional pointers need be added to the hashed table only after they are referenced for the first time. Many of these facilities are available in modern object-based programming environments [Weinreb and Moon].
The scheme described here works well for any analysis or synthesis tool the attributes of which are mostly in fixed positions. However, as the number of tools grows, efficiency may decline. To prevent new tools from operating very slowly because their attributes are all in hashed entries, the representation can provide a small amount of "private" memory for each analysis and synthesis tool. This memory is a fixed attribute that is dedicated to the particular tool. The analysis and synthesis tools can use that entry for faster access, either by placing the most important attribute(s) there or by using it as a pointer to their own private attribute information. In general, the private attribute needs to be only one word in size to be useful.
Attribute flexibility is very important in a design representation. But so is efficiency. Therefore it is worthwhile to incorporate a collection of storage techniques to achieve the best possible results. This permits the design system to be powerful and fast, even at the expense of code complexity.
In any useful design environment, much information will be stored on an object. Some of this information is specific to each object, but much of it is general to all objects of a given class. In such circumstances it is advantageous to place the common information in a single common location. This location is called a prototype (see Fig. 3.5).
Prototypes should exist for every object in a design. A single prototype defines a class of objects and describes every actual object in that class. Attributes on the actual objects point to their prototypes (see Fig. 3.6) and, if it is desired, attributes on the prototypes can head linked lists of the actual objects. New attributes to be added to the database can be placed in the prototype object if they are common to everything in the class, or they can be placed in the individual objects if they are specific to them.
Many applications work with a subset of the objects in a design. Examples include selection of objects in a particular area, on a given net, or on a certain layer. To make this selection, some criterion is applied to the database and those objects in the subset are marked for future analysis. This intermediate marking step is necessary because the selection algorithm may be very time consuming and the analysis code repeated often. For this reason it is important to be able to mark efficiently a selected subset of objects for rapid subsequent identification.
The obvious marking technique is to set a flag on an object when it has been selected. This flag is a Boolean attribute on the object and so it consumes little space. The analysis phase needs only to examine the flags to determine the state of the object. The problem with marker flags is that their use requires multiple passes of every object in the design: one pass to clear all the flags, one pass to mark the desired objects, and one pass for every list of selected objects that is requested. The flag-clearing pass is the only one that will necessarily require a complete scan of the design, because many selection and examination algorithms work locally. However, they all require that the flags on every object be properly set. If the flag clearing is done after the analysis rather than before the marking, then the final analysis pass can be used to clean up the flags. This might save time but it is not a safe technique and results in a less robust program. Thus the use of flags as object markers is acceptable but potentially slow in large design databases.
A better marking technique is the use of time stamps. A time stamp is an integer attribute that is stored in an object when that object is selected. The value of the stamp is changed before every marking pass so that old stamp values become automatically invalid. The analysis pass then looks for time-stamp values equal to the current one that was used in marking. In addition, time-stamp values can be manipulated in such a way that extra information is encoded in the stamp value. The advantage of time stamps is that they do not have to be cleared and so they do not require that extra complete database scan. The disadvantage is that they consume an entire word of 32 or more bits to represent (be warned: small integer time stamps such as 16-bit values can overflow), whereas flags require only one bit.
When the analysis phase finds itself making complete passes of the design to find a small set of marked objects, then it is time to start accumulating the marking information outside of the database. Rather than storing marking attributes on the objects, pointers to the marked objects should be stored in external lists. These lists are as long or short as they need to be and are not dependent on the size of the design. Analysis does not have to search the entire circuit: It has its selected set in a concise list. Although this method consumes extra memory for the marking list, it actually may save memory because it does not require marker attributes in the database. The technique will take more time because the allocation, construction, and freeing of these lists is much more time consuming than is the simple setting of a flag or a time stamp, but for many applications this is worthwhile. The final decision about which marking method to use depends heavily on the nature of the selection and analysis algorithms.
Memory allocation is required in all phases of design. It typically consists of only two operations: the allocation of a specified amount of unused memory and the freeing of an allocated block. Some systems reduce this to a single operation that allocates on demand and frees automatically when the object is no longer used. Special garbage-collection operations find the unused memory by counting the number of references to each block [Deutsch and Bobrow].
Not only are objects and their attributes allocated, but temporary search lists and many other variable-length fields are carved out of free memory. It is important to deal with the memory properly to make the system run efficiently. Nevertheless, many design systems foolishly ignore the problem and trust the operating system or language environment to provide this service correctly.
One basic fact about memory allocation is that it takes time to do. Most programming environments perform memory allocation by invoking the operating system and some even end up doing disk I/O to complete the request. This means that a continuous stream of allocations and frees will slow the design system considerably. If, for example, memory is allocated to store a pointer to a marked object and then freed when the marker list is no longer needed, then every selection step will make heavy use of a general-purpose memory-allocation system. This approach is not very efficient. A better technique is to retain these allocated blocks in an internal list rather than freeing them when the analysis is done. Requests for new objects will consult this internal free list before resorting to actual memory allocation. Initially, the internal free list is empty, but over time the size of the list will grow to be as large as the largest number of these objects that is ever used.
The reason for not freeing objects is that they can be reallocated much more quickly from an internal free list. The memory allocator in the operating system cannot organize freed blocks of memory by their object nature because it knows nothing about the design program. Therefore it will mix all freed blocks, search all of them when reallocation is done, and coalesce adjacent ones into larger blocks whether or not that is appropriate. All this wastes time. The design system's own free list is much more intelligent about keeping objects of a given class together and can respond appropriately. Thus the speed of the program is improved.
Another time-saving technique is to allocate multiple objects at a time, in larger blocks of memory. For example, when the internal list of free marker objects is empty, the next request for a new object should grab a block of memory that can hold 50 such objects. This memory is then broken down into 49 free objects on the internal list and one that is to be used for the current request. This results in fewer calls to the operating system's memory allocator, especially for objects that are used heavily. In addition, some space will be saved since the operating system typically uses a few words per allocated block of memory as bookkeeping. The drawback of this block-allocation technique is that the program will typically have allocated memory that is unused, and this can be wasteful.
The biggest problem with memory allocation is that the program will run out of memory. When it does on a virtual-memory computer, the operating system will begin to page the design data onto disk. If the use of memory is too haphazard, the contents of an object will be fragmented throughout the virtual address space. Then the operating system will thrash as it needlessly swaps large amounts of memory to get small numbers of data. To solve this, it is advisable for design systems that run on virtual machines to pay special attention to the paging scheme. For example, all objects related to a particular cell should be kept near each other in memory. One way to achieve this is to allocate the objects at the same time. Unfortunately, as changes are made the design will still fragment. A better solution is to tag pages of memory with the cells that they contain. Memory used for a different cell will be allocated from a different memory page and all cell contents will stay together. By implementing virtual memory as "clusters" of swappable pages, the design activity will remain within a small number of dedicated pages at all times [Stamos].
In addition to aggregating a design by cells, clusters of virtual memory can be used for other special-purpose information such as the attributes of a particular design environment, analysis, or synthesis tool. The resulting organization will provide small working sets of memory pages that swap in when needed, causing the design system to run faster. For example, if all timing-related attributes are placed together, then those memory pages will remain swapped out until needed and then will swap in cleanly without affecting other data.
When the computer does not support a virtual address space, the design system must do its own swapping. This internal paging is typically done by having only one cell in memory at a time. The code becomes more complex because all references to other cells must explicitly request a context change to ensure that the referenced data are in memory. In virtual-memory systems, all data are assumed to be in memory and are implicitly made so. In an internally paged system, the data must be loaded explicitly. Many design operations span an entire hierarchy at once and will run more slowly if paged one cell at a time. For example, it will be harder to support hierarchical display, network tracing, and multiple windows onto different cells. Although the design system could implement its own form of virtual memory, that would add extra overhead to every database reference. It is better to have a virtual computer that implements this with special-purpose hardware. Also, letting the operating system do the disk I/O is always faster than doing it in the application program, because with the former there is less system overhead. Thus the best way to represent a design is to allocate it intelligently from a large, uniform memory arena.
If a design is going to be represented by placing it in virtual memory, then a very large design will consume much virtual memory. To modify such a design, the system will have to read the data from disk to memory, make changes to the memory, and then write the design back to disk. This is very time consuming when the design files are large and the virtual memory is actually on disk. Even nonvirtual-memory systems will waste much time manipulating large design files. What is needed for better speed is an intelligent format for disk representation.
By placing a "table of contents" at the beginning of the design file, the system can avoid the need to read the entire file. Individual parts can be directly accessed so the design can be read only as it is needed. This is fine for efficient perusal of a design but there will still have to be a total rewrite of the file when a change is made. If each cell is stored in a separate disk file, then the operating system's file manager will perform the table-of-contents function. This allows rapid change to single cells but opens up the problem of inconsistent disk files since they can be manipulated outside of the design system.
An ideal disk format would replicate exactly what is in memory. When this is done on a virtual-memory machine with flexible paging facilities, it is not necessary to read or write the entire design file at once. Instead, the file is "attached" to virtual memory by designating the disk blocks of the file to be the paging space for the design program. Initially these memory pages are all "swapped out" but, as design activity references new data, the appropriate disk blocks are paged in. Changes to the design manipulate the disk file in only those places corresponding to the modified memory. Allocation of more memory for a larger design automatically extends the size of the disk file. Of course, writing the design simply involves updating the changed pages. This scheme requires the smallest amount of disk I/O since it accesses only what it needs and does not require a separate paging area on disk.
The only problem with storing the precise contents of memory on disk is that object pointers do not adjust when written to disk and then read back into a different address in the computer. If relocation information is stored with the file, then each page must be scanned after reading and before writing to adjust the pointers. This requires extra time and space in addition to creating the problem of having to identify every pointer field in memory. Relocation could be done with special-purpose hardware that relocates and maintains pointer information in memory and on disk. Unfortunately, no such hardware exists. The only way to avoid these problems and still obtain a single representation for disk and memory is to stop using pointers and to use arrays and indices [Leinwand]. This makes I/O faster but slows down memory access during design.
The last general issue in representation to be discussed here is the control of changes. These changes come from the synthesis tools, from the analysis tools, and from that most advanced tool of all, which does both synthesis and analysis, the user interface. Once a change is requested, it might be further transformed by side effects within the database that produce more modification. These side effects are constraints that tie together different pieces of the database so that a change to one results in a change to the others. Such constraints belong in the database as an integral component of change so that the database can guarantee their uniform and consistent application. The original change, combined with the effects of constraints, forms a constrained set of changes that should be retained for possible reversal. Undo control also belongs in the database because there may be many sources of change in the design system, all of which wish to guarantee that undo will be possible. Thus database modification actually involves a change interface, constraint satisfaction, and undo control.
The interface to database modification should be a simple set of routines. When the representation consists of objects with attributes, it is sufficient to have routines to create and delete objects and to create, delete, and modify attributes. In practice, however, there are different types of objects with differing attributes, so special interfaces will exist to manipulate each object. Also, some attributes come in sets and should be modified together. For example, a single routine to change the size of an object will affect many coordinate attributes, such as the bounding area, the corner positions, and the aspect ratio. Although these side effects can be implemented with constraints, efficiency considerations dictate that separate routines exist to implement the frequently used functions.
In a VLSI design system, manipulation routines should be provided for the basic aspects of circuit elements. This means that there should be interfaces for manipulating hierarchy, views, connectivity, and geometry. Hierarchy manipulation requires routines to create and delete cell definitions and their instances. View manipulation requires routines to deal with correspondence pointers throughout the database. Connectivity manipulation means having routines to create and delete components and wires. Finally, geometry manipulation needs routines to alter the physical appearance of an object.
Constraint can appear in a number of different forms. Typically, an object is constrained by placing a daemon on it, which detects changes to the object and generates changes elsewhere in the database. When two objects are constrained such that each one affects the other, then a single daemon can be used that is inverted to produce a constraint for both objects. For example, if two objects are constrained to be adjacent, then moving either one will invoke a constraint to move the other. A more complex constraint can involve three or more attributes. An example of this is simple addition, in which one attribute is constrained to be the sum of two others. If any attribute changes, one or both of the others must adjust.
Constraint specification can be made simple by demanding certain restrictions. One way to do this, when constraining more than one object, is to require a separate constraint rule on each object so that there is always a rule waiting for any change [Batali and Hartheimer; Steele]. For example, when three attributes are constrained, a rule must appear for each one specifying what will happen to the other two when a change occurs (see Fig. 3.7). If this is not done, the database will have to figure out how to satisfy the constraints by inverting one rule to get the other. Another way to simplify constraint specification is to restrict the allowable constraints to a simple and solvable set. The Juno design system allows only two constraints: parallelism and equidistance [Nelson]. The Electric design system has the limited constraints of axis orthogonality and rigidity (see Chapter 11). These constraints are simple enough that no complex rule inversion is needed because all rules and their inverse are known a priori.
| ||||||||||||||||||
| FIGURE 3.7 Constraint rules for "A + B = C". | ||||||||||||||||||
More complex constraint systems have the advantage of allowing the user to build powerful design facilities. Total constraint flexibility can be found in Sketchpad [Sutherland] and ThingLab [Borning]. These constraints are generalized programming-language expressions that are solved by precompiling them for efficiency and by using error terms to indicate the quality of satisfaction. Solution of such constraints is not guaranteed and can be very time consuming (see Chapter 8, Programmability, for a discussion of constraint solving).
Representation of constraint can take many forms. In limited-constraint systems such as Juno and Electric, the constraints are simply sets of flags on the constrained objects. In more complex systems, the constraints are subroutines that are executed in order to yield a solution. These database daemons detect changes to constrained objects and pursue the constrained effects. In addition to methods for storing and detecting constraints, there must be special structures to aid in constraint application. For example, there should be attributes to prevent constraint loops from infinitely applying the same set of actions. A time stamp on an object can be used to detect quickly when a constraint has already executed and is being run for the second time. When such a loop is detected, it indicates that the database may be overconstrained and that special action is necessary.
When a requested change and all its resulting constraints have been determined, the system is left with a set of constrained changes to the database. Some of these were explicitly given and others were the implicit results of constraints. The implicit results should be returned to the subsystem that invoked the change. However, these results may be intermingled with the explicit changes and may make no sense when out of order. For this reason, changes must be collected in the proper sequence, regardless of whether the change came directly from the application program or from internal constraints. The complete set of changes should then be presented to the application subsystem, which can then see the total effect. A uniform subroutine interface can be established for broadcasting changes, and it should mimic the one that was used to request the changes.
The collected set of changes should also be retained by the database for possible undoing. In order to enable this, the complete nature of the change must be held so that the original can be restored. This is best accomplished by having a "change" object associated with every database modification, showing what was changed and how. The change object may contain old values from before the modification or it may describe the nature of the change in such a way that it can easily be reversed. One complication is that deletion changes will have to store the entire contents of the deleted object to allow for proper reconstruction when the deletion is undone. This is not very efficient, so deletions usually just describe the operation, point to the deleted object, and delay its actual destruction while there still is a chance that the deletion will be undone.
Every change requested by an application subsystem results in a batch of constrained change objects, organized in an ordered list. The database should be able to undo such a batch of changes by tracing it backwards. A truly powerful design system will allow undoing of more than the last change and will retain an ordered history of change batches so that it can undo arbitrarily far back. Implementation of undo can be done by removing the change objects from the history list and replacing them with the undone set. This undone set of changes may be more compact because it may combine multiple changes into a single one. In such a scheme, users must understand the extent of each undo change. Also, because this scheme allows redo by undoing an undo, care must be taken to prevent indiscriminate use of the facilities that may produce an inconsistent database.
A better implementation of undo control is to back up through the history list without creating new entries. Redo is then a simple matter of moving forward through the list, and further undo moves farther backward. When a new change is introduced, the history list is truncated and extended at the current point, thus losing the ability to redo. This scheme provides a cleaner change mechanism for both the user and the implementor.
Change control is time and space consuming. It can take arbitrary amounts of time to solve constraints and produce a consistent database. Also it can take arbitrary amounts of space to represent database changes, especially when these changes are multiplied by constrained effects and saved for possible undo. However, the resources consumed by such a change mechanism are well worth the effort because they make the design system responsive and forgiving.
This chapter has shown so far that a design consists of objects with attributes. For maximum flexibility and efficiency, these should be implemented with fixed record entries, linked lists, and attribute hash tables. The objects are allocated from unused virtual memory and are represented on disk in a variety of ways to best suit the nature of the computer system. Special techniques can be used to scan and mark the database. Also, the representation of change, constraint, and undo control is a fundamental aspect of a design database.
The rest of this chapter will discuss techniques for dealing with the four aspects of VLSI design: hierarchy, views, connectivity, and geometry.
|
Prev |  |
TOC | Next | |
 |